Vista de detalle de Servicios y Procesos de Negocio
La Vista de Detalle de Servicios vinculados a un Dispositivo, permite al usuario acceder directamente a una información completa y actualizada acerca del servicio seleccionado. Toda esta información es recopilada durante las últimas 24 horas y es mostrada entre el KPI`s fijo y las siguientes secciones:
BP Trace (solo en servicios pertenecientes a un Proceso de Negocio)
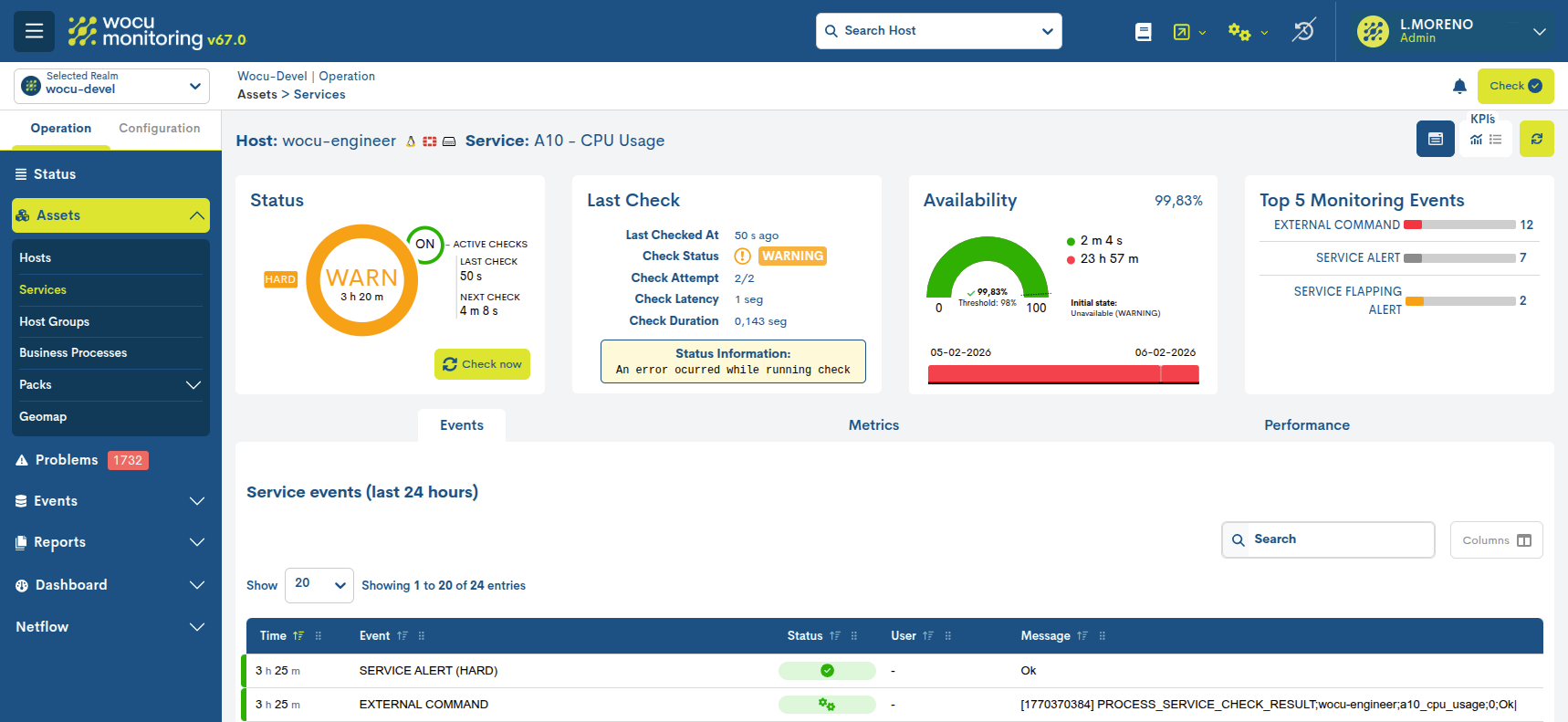
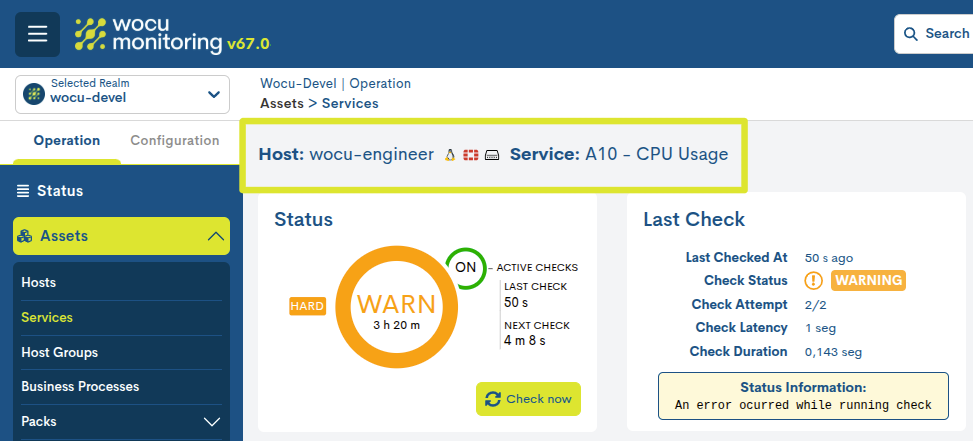
En la barra superior, junto al nombre del dispositivo, se especifica el servicio en cuestión. A continuación del nombre de cada dispositivo y servicio, el sistema fija el icono dentificativo del Pack de Monitorización al que pertenece.
Acciones sobre el servicio
Desde esta vista es posible ejecutar acciones directamente sobre un servicio de monitorización concreto, sin necesidad de acceder al inventario general. Esta funcionalidad permite realizar operaciones de forma rápida y contextual, facilitando la gestión diaria del servicio seleccionado. Además, la disponibilidad de estas acciones está condicionada por el estado actual del servicio asociado al dispositivo, garantizando que únicamente se muestren y ejecuten las operaciones permitidas según la casuística dada.
Nota
Estas acciones son las mismas que las presentes en Activos (Assets) > Inventario de Services, garantizando coherencia funcional en toda la plataforma.
Accionando el botón, se despliega un selector que muestra todas las acciones que pueden ejecutarse sobre ese servicio en concreto.
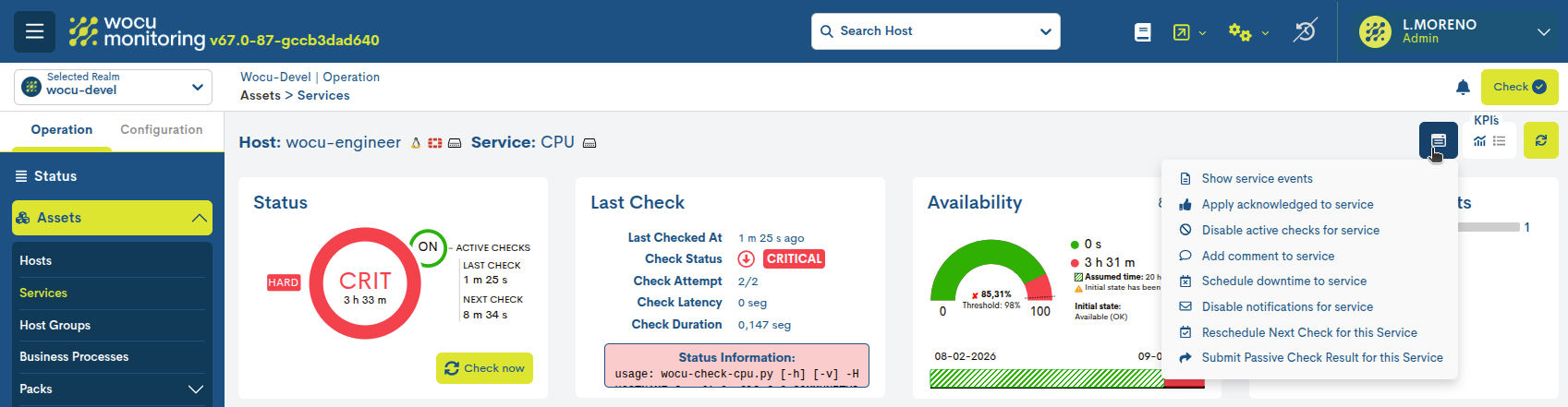
Estas son:
Mostrar Eventos del Servicio (Show services events): visualiza los eventos asociados al servicio de monitorización.
Aplicar estado aceptado o reconocido (Apply acknowledged to service): reconoce y asume el estado operacional del servicio en cuestión.
Deshabilitar chequeos activos (Disable active checks for services): gestiona la ejecución de comprobaciones.
Añadir/Mostrar comentarios (Add comment to service): añade comentarios al servicio.
Programar tiempo de caída (Schedule downtime to service): programa tiempos de indisponibilidad sobre el servicio.
Deshabilitar notificaciones (Disable notifications for service): habilita o deshabilita las notificaciones.
Reprogramar próxima comprobación (Reschedule next check for this service): programa siguientes comprobaciones del estado operativo.
Enviar resultados de comprobaciones pasivas (Submit passive check result for this service): envío manual de resultados de comprobaciones pasivas.
Importante
Una vez seleccionada la acción deseada, es necesario refrescar la vista para que el sistema inicie el proceso correspondiente y se reflejen los cambios asociados a la acción ejecutada.
Para facilitar el seguimiento operativo, los iconos representativos de cada acción se muestran en el KPI Status del servicio. Estos iconos permiten identificar de forma rápida qué acciones están habilitadas o activas en cada momento, ofreciendo una visión clara del estado operativo del servicio.
KPI`s
Este espacio muestra, una serie de paneles con indicadores clave de rendimiento y estados operativos del servicio en cuestión. Los datos son mostrados a través de cuatro paneles y son recopilados durante las últimas 24 horas.
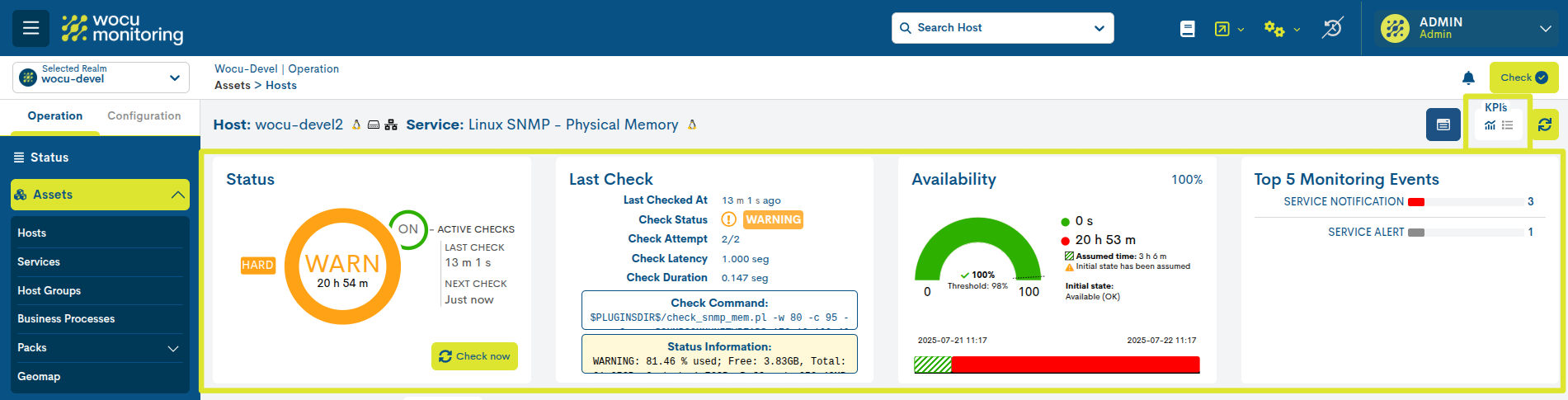
Los KPI`S pueden visualizarse de dos formas posibles:
Vista completa
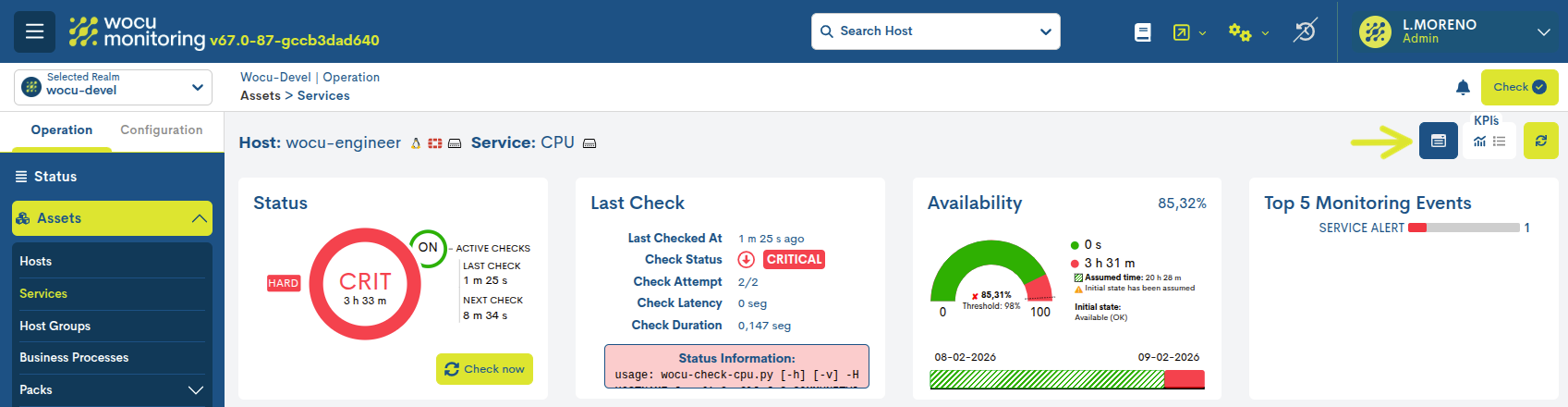
Activando el icono marcado en la siguiente imagen, se despliegan los siguientes KPI`s, con datos detallados y gráficos interactivos:
Status
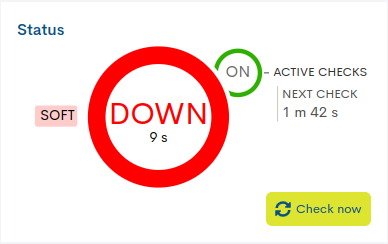
En este primer panel se indica el estado de operatividad en el que se encuentra el dispositivo y chequeos de monitorización realizados sobre el mismo. Además se ofrecen otros datos complementarios explicados a continuación.
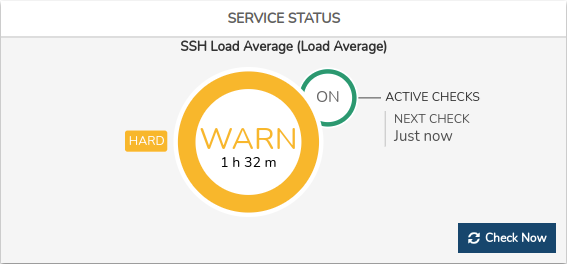
✓ Estado actual de monitorización del servicio y tiempo activo
Dentro de la circunferencia central se indica: el estado que registra el servicio y el tiempo total que lleva activo el estado actual. En la anterior imagen, el servicio lleva seis horas y doce minutos en estado WARNING.
La rápida alternancia de cambios de estados en un servicio es conocido como Flapping. En el panel también es representado con una media circunferencia en color amarillo y en su interior una flecha gris parpadeante.
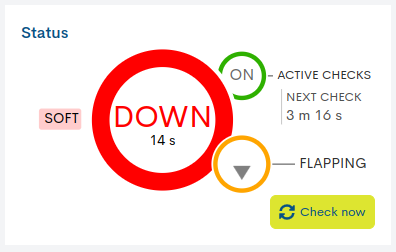
- ✓ Chequeo de monitorización: Active Checks/ Next Check
WOCU-Monitoring realiza chequeos para evaluar el estado operativo del servicio.
La circunferencia menor ON/OFF, ubicada junto a la etiqueta Active Checks, indica si la opción de chequeos está activada o desactivada. Adicionalmente, la etiqueta Next Check muestra el tiempo restante para la próxima verificación. En la imagen anterior esta función está habilitada y el siguiente chequeo se realizará en dos minutos y un segundo («Next check: 2 m 1 s»).
La opción para desactivar los chequeos de monitorización de servicios, está accesible desde la acción Deshabilitar chequeos activos (Disable active checks for services) dentro de Acciones sobre los Servicios inventariados (ℹ).
Estados Soft y Hard
Relacionado con la tarea de chequeo, este panel ofrece también una información complementaria acerca de los tipos de estados obtenidos y su nivel de gravedad, utilizando las siguientes etiquetas:
Soft: es asignado cuando el estado del dispositivo obtenido no es definitivo, ya que puede o no ser revertido en el siguiente intento de chequeo. En el caso de superar el número de intentos predefinidos, obteniendo estados negativos, el nivel de gravedad de error se elevará a tipo HARD. El objetivo es evitar falsas alarmas por problemas transitorios.
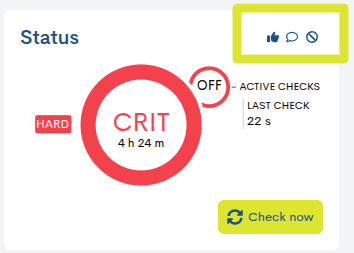
Hard: es asignado cuando el estado del dispositivo obtenido es erróneo continuamente, sin llegar a ser corregido. Es decir, cuando el dispositivo devuelve un estado negativo en el primer intento y también en los chequeos posteriores superando el número de intentos predefinidos. Esta nueva situación ya sí es notificada al usuario contacto.

✓ Iconos de acciones aplicadas sobre el servicio
Cuando un servicio tiene acciones habilitadas o en ejecución, el widget mostrará iconos representativos de cada acción. Estos iconos permiten identificar de manera rápida qué acciones están activas en cada momento, ofreciendo una visión inmediata y clara del estado operativo del servicio.
Las posibles acciones son explicadas en el siguiente punto: Acciones sobre el servicio.
Last check information
Este panel ofrece información relacionada con el último chequeo realizado al servicio en cuestión. Los datos ofrecidos son:
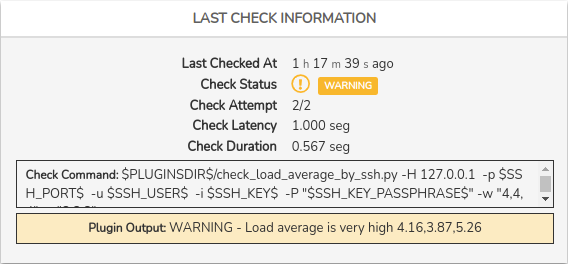
✓ Last checked at: indica hace cuánto se ha realizado el último chequeo al servicio.
✓ Check status: indica el estado resultado del chequeo ejecutado.
✓ Check attempt: indica el número de intentos que deben realizarse (obteniendo un resultado erróneo), para que el servicio pase de nivel de error SOFT a HARD. Por ejemplo, en la anterior imagen, está definido que después de dos chequeos fallidos, se eleve el nivel de gravedad de error de SOFT a HARD.
✓ Check latency: es la diferencia entre el tiempo de chequeo programado y el tiempo de ejecución real, es decir, indica el tiempo de retardo del chequeo.
✓ Check duration: tiempo que ha tardado el servidor en dar una respuesta de chequeo.
✓ Check Command: especifica el comando de chequeo completo que ha sido ejecutado para determinar el estado del Servicio. Debido a los datos de carácter sensible que puede mostrar, esta información solo será visible previa habilitación de la opción Mostrar vista completa de ejecución de comandos (Show full check command) en las Preferencias de usuario (User preferences).
✓ Status Information: mensaje de salida obtenido con información relativa a la situación actual del Servicio. La naturaleza de los mensajes variará en función del tipo de activo y su configuración.
Availability
Este panel cuenta con dos elementos gráficos que ofrecen información relacionada con el nivel de disponibilidad del servicio en cuestión.
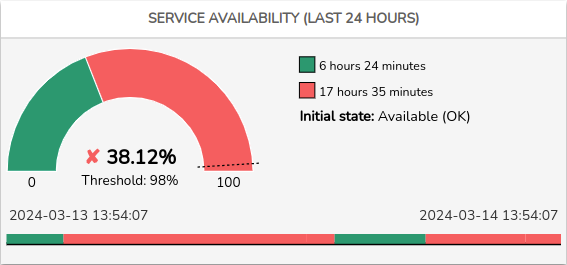
Gráfico circular
Representa el porcentaje alcanzado de disponibilidad del servicio en las últimas 24 horas. El valor porcentual es indicado en el interior del gráfico, junto con el umbral de disponibilidad mínimo establecido (Threshold) por el usuario, marcado en el gráfico con una línea discontinua.
En función del cumplimiento o incumplimiento de dicho umbral, aparecerá delante del porcentaje de disponibilidad un “✓” en color verde cuando la disponibilidad supere el valor fijado, o una “X” en color rojo en caso contrario.
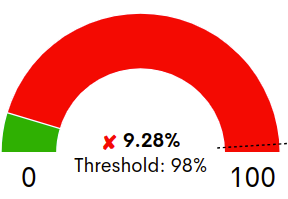
En este ejemplo, el porcentaje de disponibilidad obtenido (9.28%), está por debajo del umbral establecido (98%).
Barra temporal
Esta barra temporal ofrece un histórico de la disponibilidad del servicio a lo largo de las últimas 24 horas, mostrando el momento exacto o periodo de tiempo en el que no ha estado operativo.

La leyenda complementaria informa del periodo de tiempo (en días, horas y segundos) de disponibilidad (color verde) y no disponibilidad (color rojo) del servicio.
Además existe la posibilidad de que el sistema no haya recopilado suficientes datos para determinar el estado inicial de un servicio. En este caso, el usuario podrá asumir y asignar un estado de partida. Esta nueva situación también es registrada y visualizada en la barra temporal y en la leyenda:
Initial State: indica el estado definido por el usuario, para el periodo temporal que será asumido. Este valor se configura en las Preferencias de usuario (User preferences), concretamente en el filtro Estado inicial para el Dispositivo en SLA (Status Initial SLA Host).
Assumed time: indica la duración total del evento asumido y es representado en la barra con un estampado rallado. El usuario puede configurar el estado inicial del servicio en las Preferencias de usuario (User preferences), concretamente en el filtro Estado inicial para el Servicio en SLA (Status Initial SLA Service).
Top Monitoring Events
Este panel informa a través de un máximo de cinco barras, los tipos de Eventos (Events) más frecuentes en las últimas 24 horas, para el servicio en cuestión.
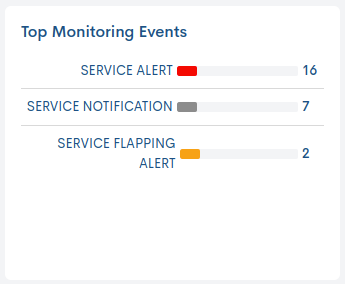
La leyenda indica el tipo de evento al que hace referencia cada barra, y en cada una de ellas se indica el número de veces que se ha producido un evento. Situando el cursor sobre una barra, se visualiza un mensaje emergente con el tipo de evento, más su valor total de ocurrencias.
Los diferentes tipos de Events son explicados en detalle en el campo Evento, del apartado Campos del listado de Eventos de Monitorización.
Vista resumen
Activando el icono marcado en la siguiente imagen, se despliegan los anteriores KPI`s, pero en un formato más compacto para una lectura rápida:

Asimismo, es posible ocultar el bloque de paneles mediante la conmutación de ambos botones.
Events
Los Eventos de un servicio determinado son almacenados y presentados en esta pestaña. Se muestran todos los mensajes de eventos de monitorización producidos en las últimas 24 horas, relacionados con el servicio en cuestión.
Este listado brinda al usuario una información similar a la ofrecida en la sección de Eventos (Events), para un reino determinado. Por lo tanto, los campos disponibles en esta tabla son explicados de forma detallada en Campos del listado de Eventos de Monitorización.
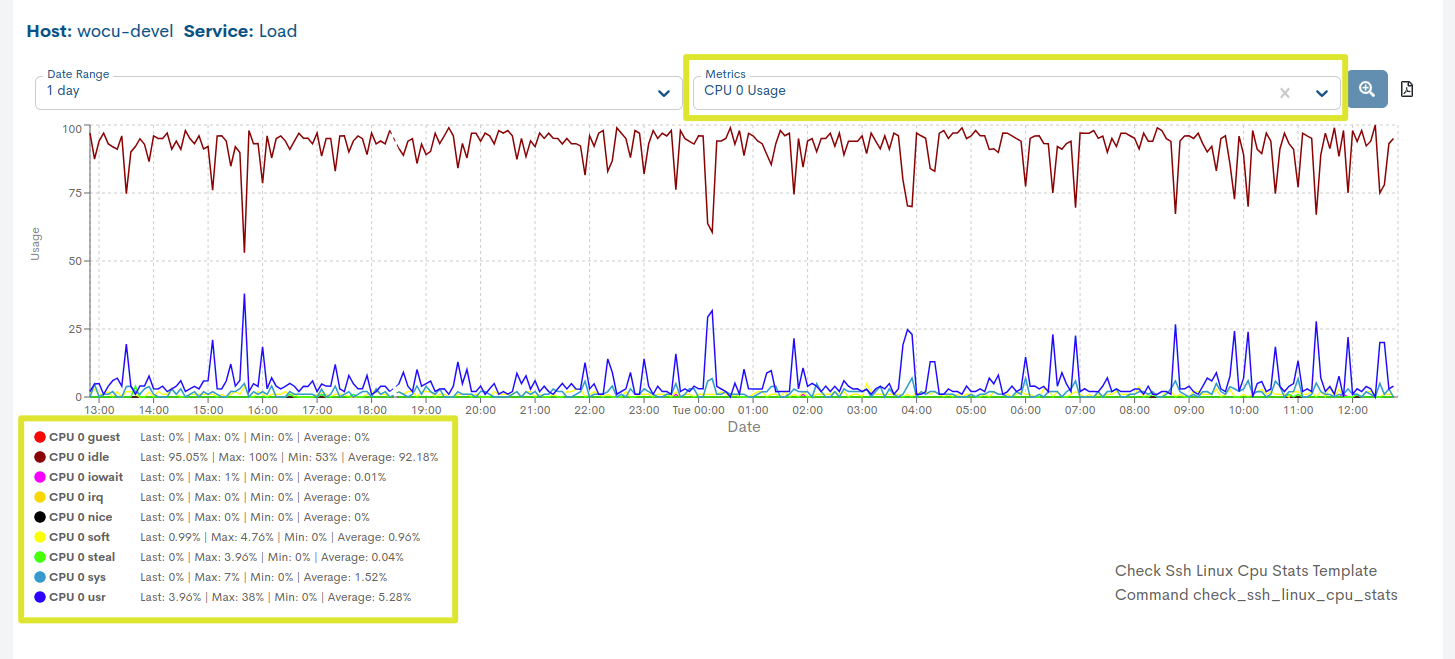
Metrics
Esta vista ofrece información precisa sobre la evolución y operatividad del Servicio seleccionado, mediante valores de rendimiento recogidos por WOCU-Monitoring y almacenados en métricas durante un chequeo. Se visualizan a partir de gráficas que muestran datos recopilados en periodos de tiempo concretos, además de indicar umbrales definidos de estados Warning y Critical.
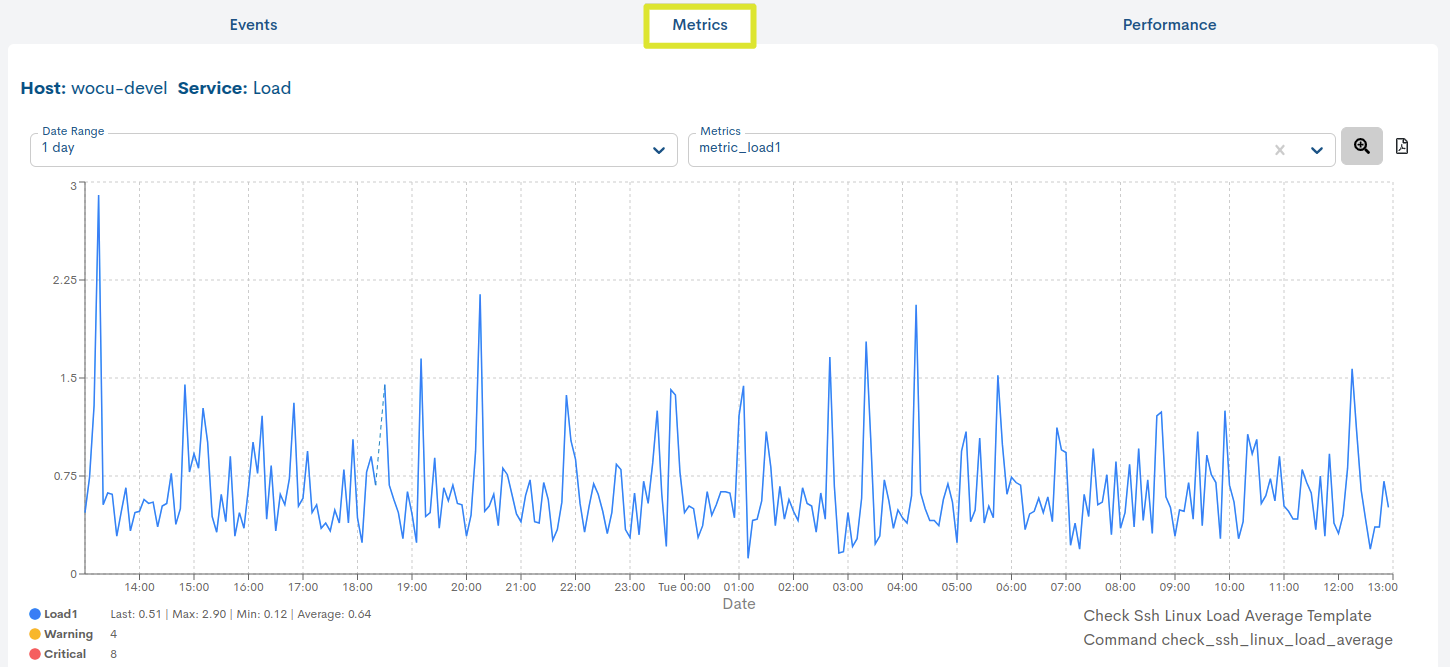
La gráfica es interactiva y permite las siguientes acciones:
Selección de un rango de fechas para la visualización de los datos
Por defecto viene prefijado en 1 día (1 day), pero existen otros criterios temporales a elección como: 4 horas (4 hours), 1 semana (1 week), 1 mes (1 month), 1 año (1 year) y rango de fechas personalizado (Custom Range).
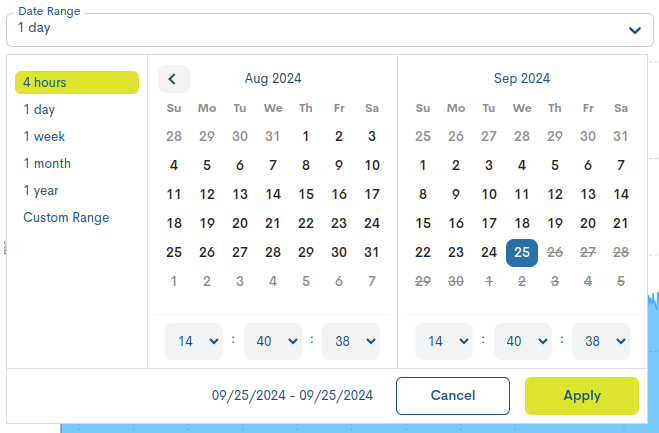
En el caso de querer establecer un periodo de tiempo determinado existe la opción Custom Range. Para configurar el marco temporal es necesario establecer una fecha de inicio y una fecha de fin. Pulsando sobre uno de los días, se establecerá esta fecha como selección, quedando marcada con un fondo azul. Además del día se puede establecer una hora en concreto de esa jornada, para ello hay que utilizar los desplegables de las casillas hora, minuto y segundo, hasta configurar la hora deseada.
Atención
Lógicamente no es posible elegir fechas de inicio y fin posteriores a la fecha actual, ni establecer una fecha de fin anterior a la fecha de inicio.
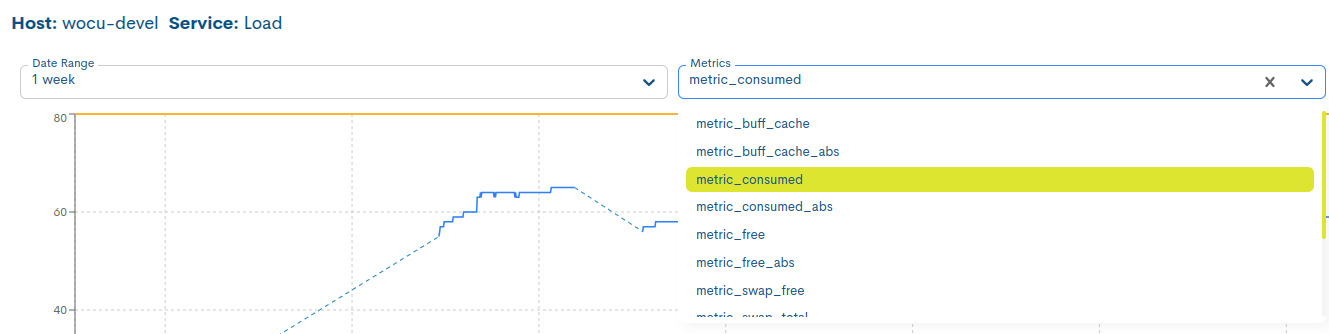
Selección de la métrica cuya información se quiere visualizar
A diferencia de las métricas fijas de un Dispositivo (RTA y PL), en el caso de servicios estas variarán en función del tipo. Véase en el siguiente ejemplo:
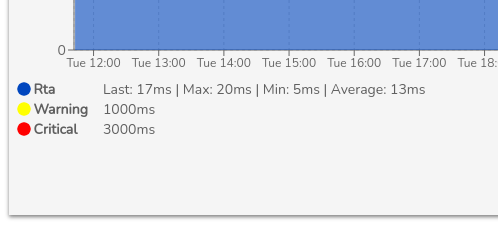
Nota
Gracias a la opción Show Critical Reference (Botón con una lupa) y a la leyenda
de colores, es sencillo identificar los
valores tanto de la métrica, series o umbrales de cambio de estado:
Warning (color amarillo) y Critical (color rojo). Adicionalmente junto a la
leyenda se proporcionan los valores máximos (max), medios (avg) y los
últimos (last) registrados.
Por otro lado, cuando no existían datos métricos disponibles para unos puntos específicos en el tiempo, la línea mostrará una línea intermitente que facilita la identificación de esos espacios nulos.
Supervisar todas las series de una métrica en una gráfica
Las series capturadas de una misma métrica son representadas en una única gráfica. Esto facilita la supervisión de los recursos en una escala más amplia, ya que permite comparar y analizar todas las series relacionadas con una métrica en un solo lugar.
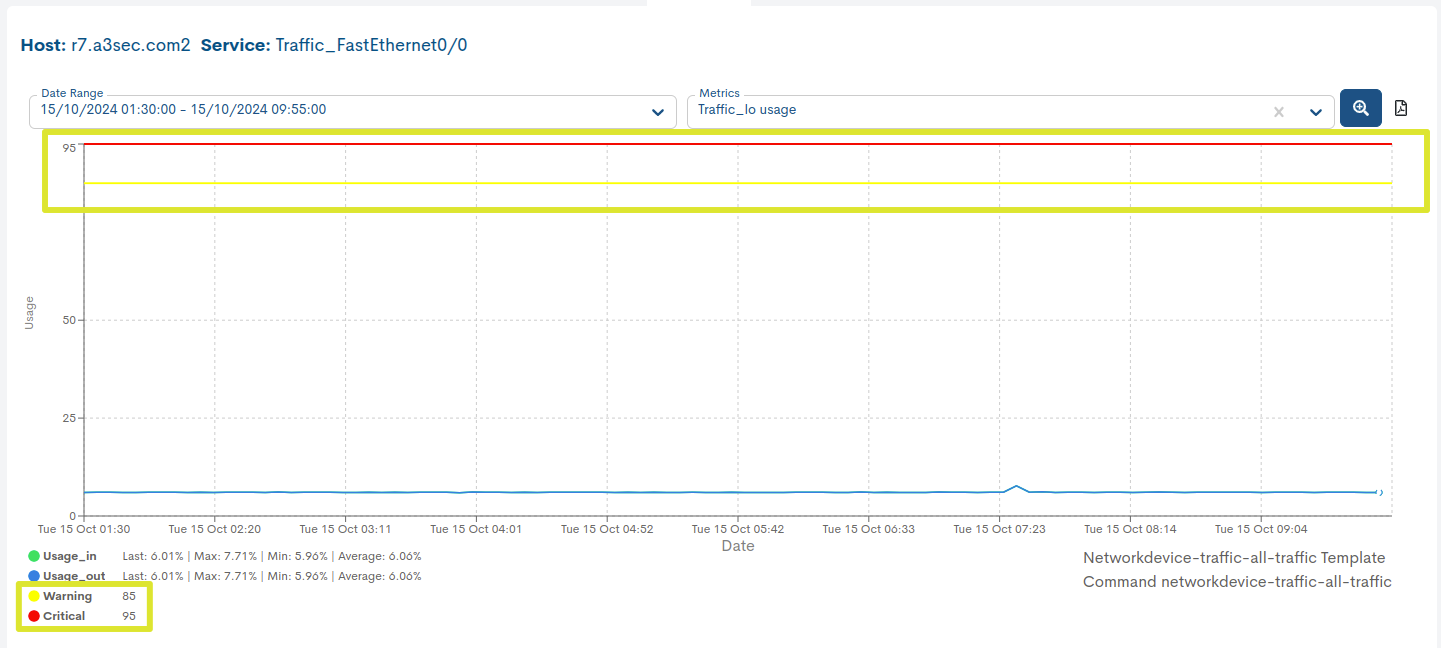
Thresholds dinámicos
Este parámetro establece el valor (en porcentaje) del umbral mínimo de nivel de servicio que se considera adecuado o aceptable.
Las gráficas métricas de Servicios aceptan Thresholds dinámicos, lo que implica que este valor ya no es fijo y puede ajustarse dinámicamente dentro de un rango predefinido. Esta función otorga una mayor flexibilidad y adaptabilidad en la gestión de los niveles SLA.
En la siguiente gráfica, se puede observar cómo los estados Warning y Critical ahora están configurados con esta nueva función, representados de acuerdo con los rangos definidos para cada uno de ellos.
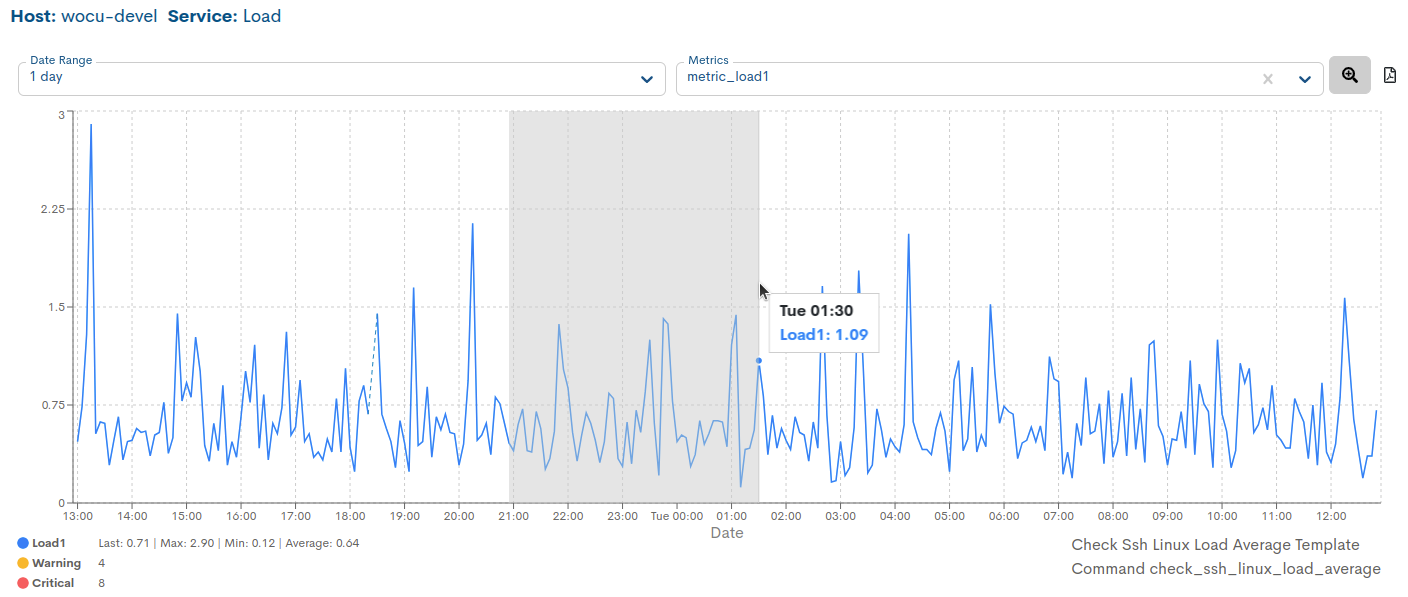
Selección de intervalos de una métrica en la propia gráfica
Además de poder seleccionar rangos temporales (ya prefijados) para métricas determinadas, es posible seleccionar manualmente intervalos y sub-intervalos en la serie de datos y visualizar una gráfica de los mismos.
La selección se realizará directamente en la propia gráfica haciendo uso del ratón. Para ello, es necesario situar el ratón en el área de la gráfica generada. Cliqueando y arrastrando con el botón izquierdo del ratón, se seleccionará un sub-intervalo dentro del intervalo que estemos visualizando.
Una vez seleccionado el intervalo, podemos liberar el botón izquierdo del ratón, acción que dará como resultado la actualización de la gráfica mostrando únicamente el intervalo definido.
Además, en la barra superior de rango de fechas, se especificará el periodo temporal correspondiente a la selección manual aplicada.

Para retroceder a la gráfica inicial (según el rango escogido previamente), habrá que volver a aplicar el filtro y los datos mostrados quedarán reestrablecidos.
Nota
Esta acción puede repetirse indefinidas veces, obteniendo cada vez un rango seleccionado más pequeño que el anterior.
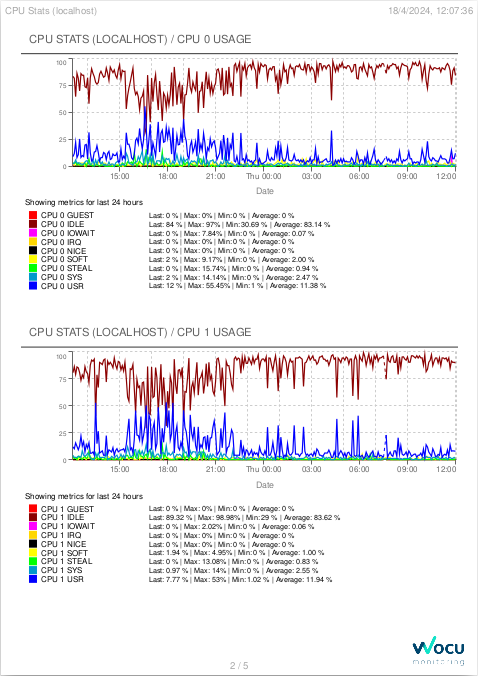
Exportación de las gráficas en PDF
A través del botón Export se facilita la descarga de un informe en formato PDF de todas las gráficas métricas del servicio en cuestión. Si el número de gráficas es muy grande las mismas se extenderán a lo largo de varias páginas
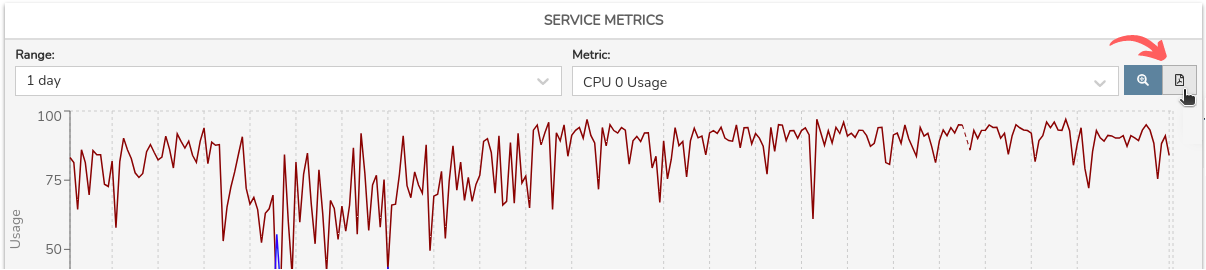
Tras hacer clic sobre el botón de exportación, automáticamente se iniciará un fichero al disco duro, para su tratamiento o uso posterior.
BP Trace
La pestaña BP Trace, visible solo en servicios pertenecientes a un Proceso de Negocio (Business Processes), muestra al usuario un árbol trazado a partir de la Regla de Negocio (BP Rule) definida previamente. Gracias a la representación con nodos y relaciones lógicas, además de conocer el estado del Proceso de Negocio, el usuario podrá analizar y localizar la causa raíz de un estado de monitorización anómalo.
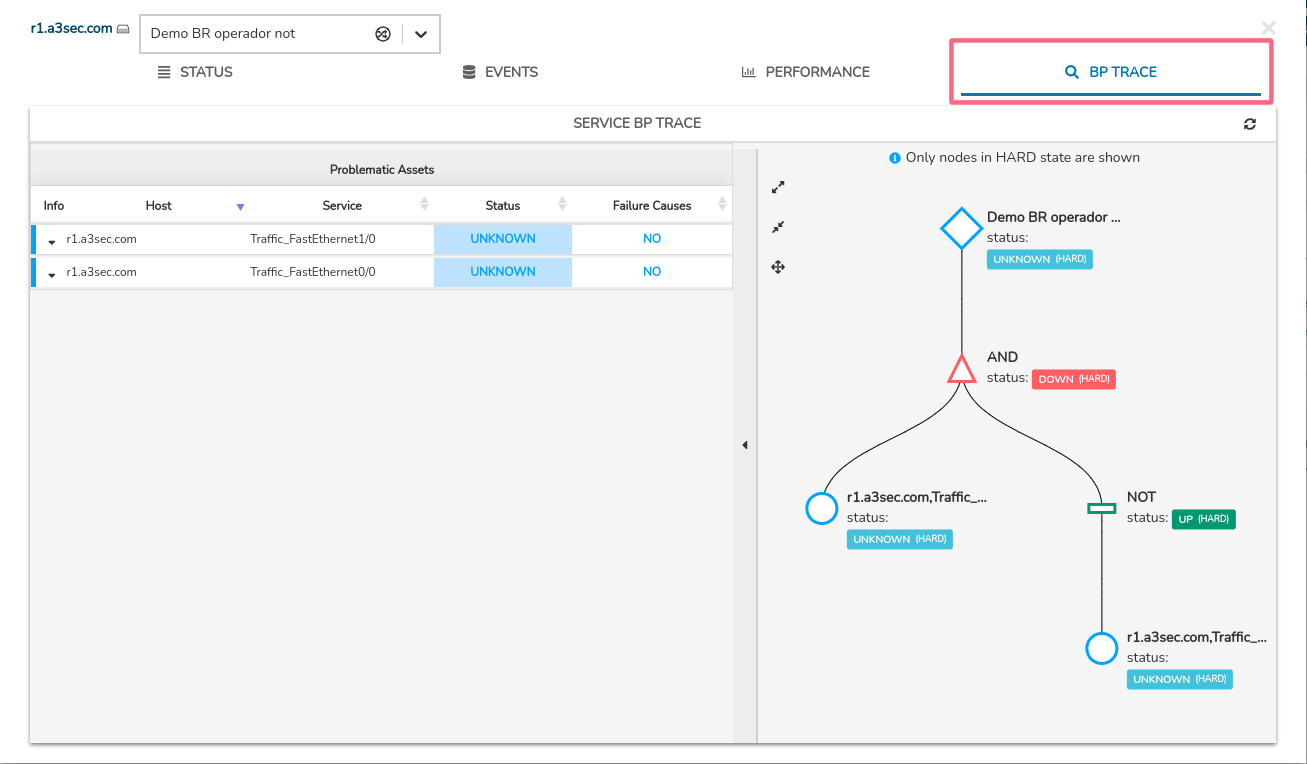
Recuerda
Habiendo establecido la Regla de Negocio, WOCU-Monitoring en un primer momento evaluará el estado de cada elemento integrante del Proceso de Negocio. A continuación, tomando en consideración estos estados individuales y los operadores lógicos que vinculan y relacionan los elementos del Proceso de Negocio, el sistema calculará y determinará un estado para el mismo.
Por otro lado, el sistema solo considera estados de tipo HARD para determinar el estado general del nodo. Por lo tanto, cualquier cambio interno de tipo SOFT será rechazado y no afectará el cálculo de estados de monitorización.
Importante
Accede al apartado BP Trace y conoce en detalle esta vista.
Edición del BP Services (Edit BP Services)
A través del botón Edit BP Services ubicado en la parte superior derecha de la vista detalle, el usuario puede efectuar cambios en la configuración del BP Service en cuestión.
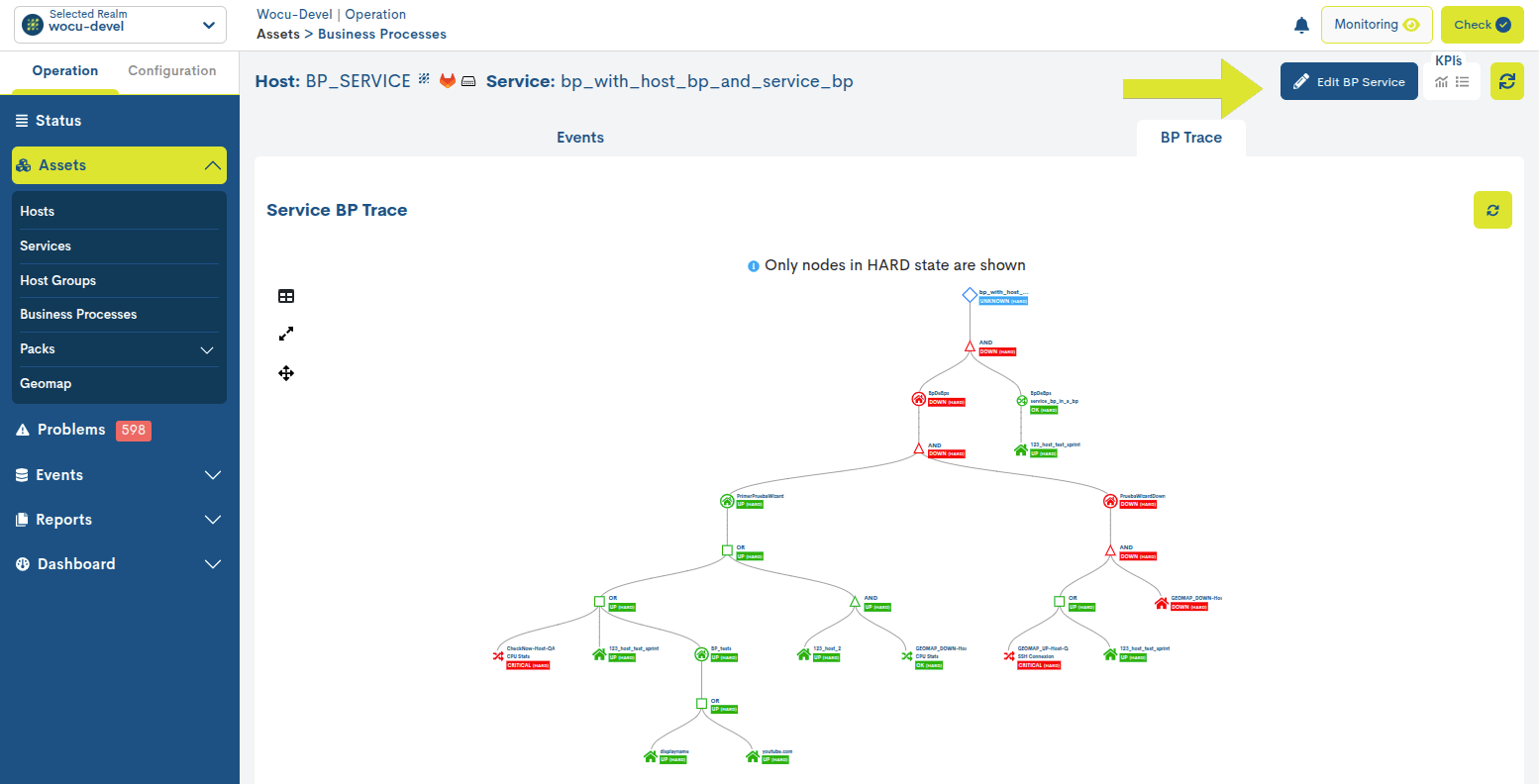
A continuación, se muestra el formulario de edición y configuración para un BP Service. Los campos a editar coinciden con los descritos en Añadir Servicios de Procesos de Negocio (+ Add).
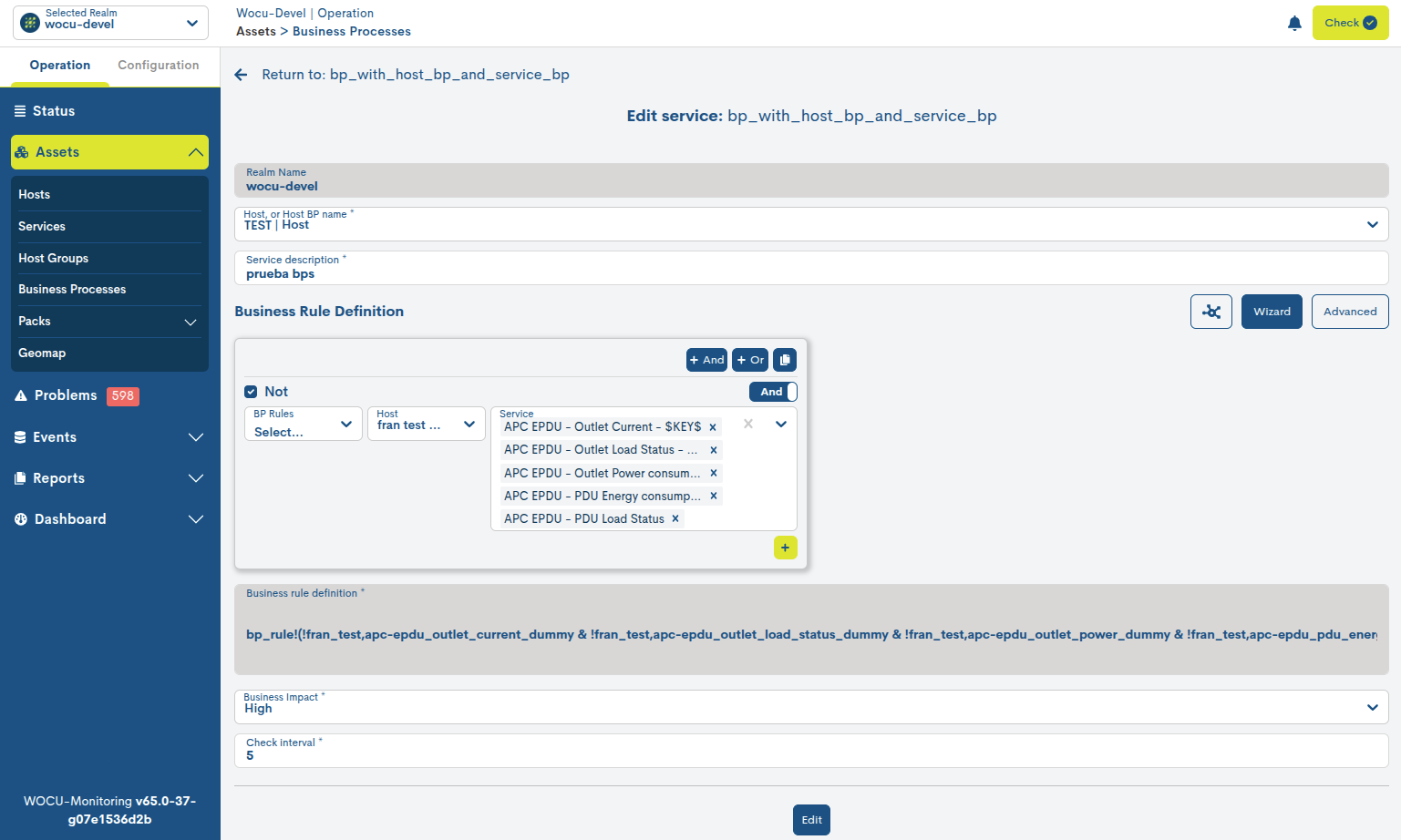
Importante
La acción de edición solo estará habilitada en Reinos estándar, es decir, estará oculta para Reinos basados en Grupos de Dispositivos (Hosts Groups) y Multireinos (Multirealm).
Una vez modificados los datos en los campos correspondientes, habrá que pulsar el botón azul Edit para salvar la configuración realizada hasta el momento, pudiendo seguir editando el formulario.
Performance
La vista Performance recopila las métricas de monitorización generadas tras las comprobaciones que el servicio lanza al Dispositivo del que depende. Cada métrica registra valores de rendimiento y capacidad, permitiendo un análisis más profundo del servicio, y por consiguiente, del Dispositivo en términos de disponibilidad.
Recuerda
Un Pack monitoriza Dispositivos mediante servicios, que a su vez generan métricas de monitorización. Las métricas adquieren como umbrales y márgenes métricos, los valores de las macros de configuración de un pack.
Véase el siguiente ejemplo:
El pack LINUX-SNMP, genera
el servicio Disk que tras cada comprobación obtiene las métricas
de monitorización: /run_used_pct, /_used, /boot_used, etc.
El conjunto de valores es presentado a través de un formato tabular, donde se incluye una entrada por cada métrica, lo que facilita su estudio individualizado.
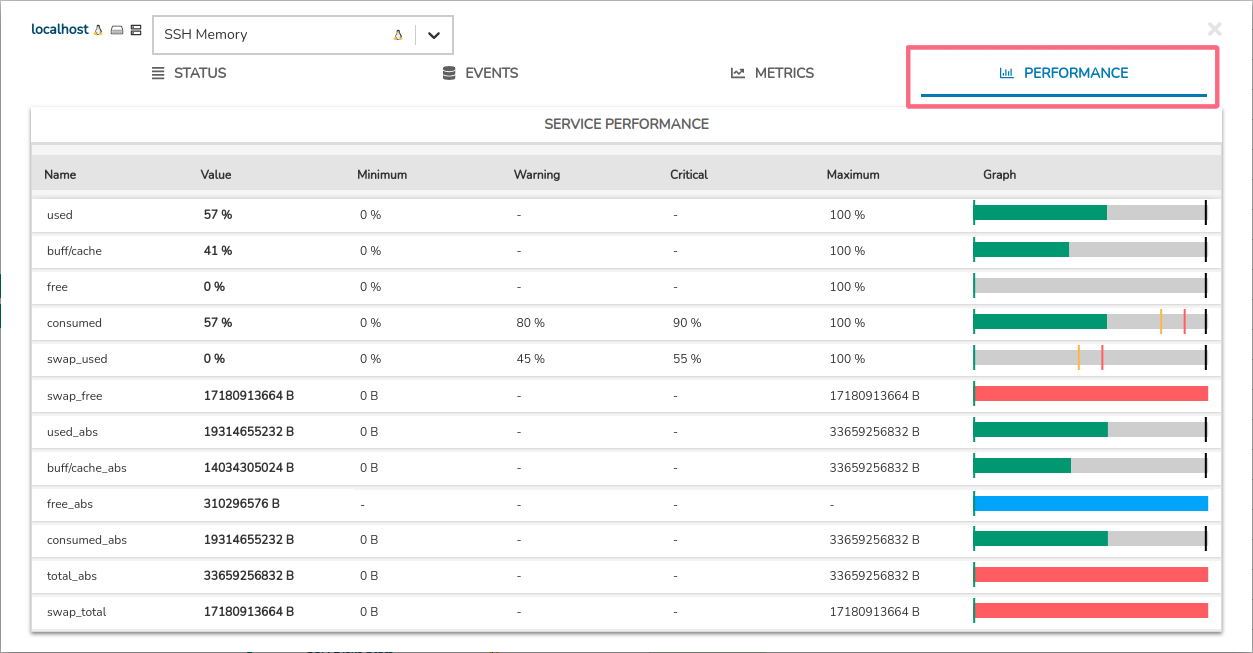
Los datos se distribuyen en las siguientes columnas, clasificadas en tres bloques:

1. Datos de la métrica de monitorización:
Name: nombre de la métrica de monitorización.
Value: último valor de rendimiento registrado en dicha métrica. El sistema realiza conversiones automáticas de valores, transformando unidades a otras más prácticas y legibles (por ejemplo, de bps a Kbps, o de ms a s) y sin realizar conversiones manuales, ya que los valores se presentan convertidos por defecto.
Esto conlleva, a que en una misma celda de la columna Value, pueden aparecer diferentes unidades en momentos distintos. Esto se debe a que el sistema asignará la unidad más adecuada en función del valor registrado. Por ejemplo, una métrica puede mostrarse en Kbps un día y en Mbps otro, si ha habido un mayor uso del recurso. Esta adaptación es dinámica y automática.
2. Umbrales de medición:
Minimum: umbral mínimo definido que puede alcanzar la métrica. Se identifica con una línea vertical en color verde posicionada (normalmente) en el inicio de la barra. Si el valor métrico registrado está por debajo del umbral, la barra del mínimo se trasladará al extremo derecho.
Warning: umbral definido a partir del cual la métrica alcanzará un estado de advertencia o alarma. Se identifica con una línea vertical en color naranja.
Critical: umbral definido a partir del cual la métrica alcanzará un estado crítico. Se identifica con una línea vertical en color rojo.
Maximum: umbral máximo definido que puede alcanzar la métrica. Se identifica con una línea vertical en color negro posicionada (normalmente) al final de la barra.
Atención
Los umbrales métricos se definen o modifican en la configuración del Pack de Monitorización de manera genérica, mediante la configuración de macros específicas. El sistema utilizará los valores que vienen por defecto en el pack cuando no hayan sido añadidos por el usuario.
3. Graficado de la métrica:
Graph: se representa gráficamente el valor actual de la métrica (columna Value) mediante una barra rectangular de longitud proporcional al valor registrado. Como puede observarse, habrá una gráfica para cada una de las métricas del servicio de monitorización.
Su comportamiento es muy sencillo, cuando la barra avance y supere el umbral establecido, el color cambiará en función del margen alcanzado.
Los umbrales actúan como indicadores y se representan con líneas verticales ubicadas a lo largo de la barra. Cada umbral tiene asociado un color identificativo.

La distinción de colores es la siguiente:
Color gris claro: indica la ausencia de datos métricos (valor = 0).

Color gris oscuro: indica que el valor es menor al mínimo establecido.

Color azul: indica la existencia de un valor registrado pero ausencia de umbrales de alerta. Esta situación genera cierta incertidumbre sobre la situación real de la métrica.

Color verde: indica que el valor está por encima del valor mínimo y por debajo de los umbrales de alerta.

Color naranja: indica que el valor está por encima del umbral WARNING pero sin exceder los umbrales superiores.

Color rojo: indica que el valor está por encima del umbral CRITICAL o superior.
